
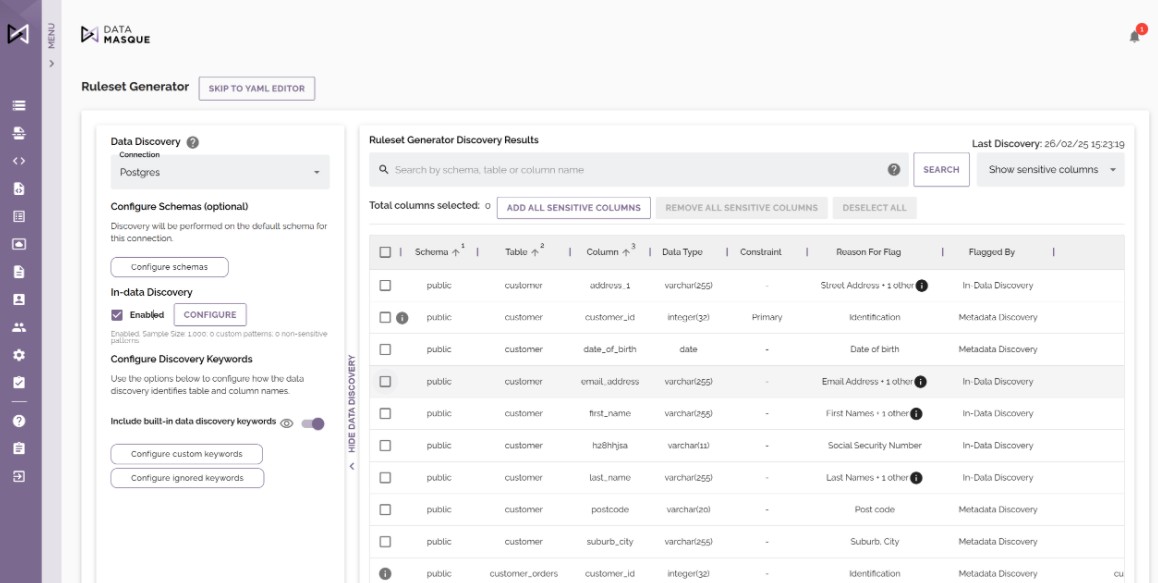
By de-identifying sensitive data while maintaining the utility of that data before it enters an AI or ML workflow.
DataMasque replaces personal and sensitive information with ‘synthetically identical’ equivalents while preserving structure, relationships and behavior.
This allows teams to work with production-like datasets for AI training, experimentation and fine-tuning, without using real customer data.